Transformers
Seq2Seq에서 RNN을 아예 빼버리고 attention으로 구성해보면 어떨까? → Transformer의 구조 현재는 seq2seq + attention에서는 하나의 벡터로…
2025/04/27
NEW POST
Jinsoolve.
복잡한 수학이나 구현 과정을 텐서플로우에서 이미 구현해 놓았다. 이를 사용하는 법을 알아보자.
텐서플로우의 함수나 여러가지 기능들은 어느정도 생략하겠다. 사용하면서 익히는 것이 가장 좋다.
Keras는 Tensorflow의 Wrapper이다. 텐서플로우 내의 구현된 keras를 이용하여 텐서플로우를 보다 쉽게 이용할 수 있다.
batch() 메소드를 이용하여 미니배치로 나누어 훈련시킨다. 훈련시킬 때는 fit() 메소드를 이용하여 훈련시킨다.
tf.keras.Sequential() 클래스를 이용해서 모델을 만들 수 있다. add() 메서드를 이용해서 층을 추가할 수 있다.
이외에도 tf.keras.Model() 클래스를 상속하여 모델을 정의할 수 있다.
마지막으로 keras의 compile(), fit() 메서드를 사용하여 컴파일하고 훈련할 수 있다.
밑바닥에서부터 모델을 재정의하여 사용할 수 있다. 불편하긴 하지만 그만큼 내가 원하는 방향으로 수정할 수 있다.

위 그림처럼 객체를 만든 후 build() 메서드를 이용하여 모델 층과 파라미터를 마드는 방법을 변수 지연 생성이라고 한다.
compile과 fit 메서드를 사용해 보겠다.

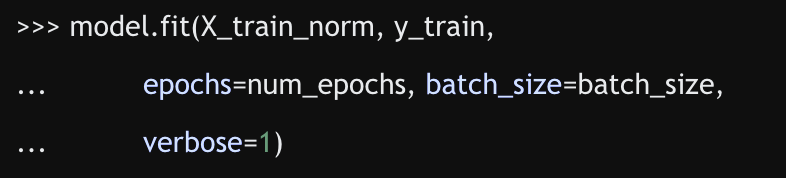
이런 식으로 모델을 컴파일 및 학습시킬 수 있다.
텐서플로우에서 구현해 놓은 신경망 클래스이다. 사용하기 편하다.
구현된 Sequential 클래스 모델에 완전 연결 층 Dense 은닉층을 추가하여 구현한다.


손실함수, 최적화방식, 평가지표 등을 정해서 컴파일할 수 있다.
참고로 컴파일함수는 모델을 어떻게 학습시킬지에 대한 설정을 지정하는 메서드이다.
ModelCheckpoint 콜백을 사용하여 모델을 훈련시키면서 최고의 성능을 내는 가중치를 저장할 수 있다. 또한 지정된 에포크 횟수(patience 매개변수)동안 평가지표가 개선되지 않으면 EarlyStopping 콜백함수를 이용하여 훈련을 멈추게 할 수 있다.
텐서보드(TensorBoard)를 사용하여 학습과정 및 계산 그래프를 시각화할 수 있다.
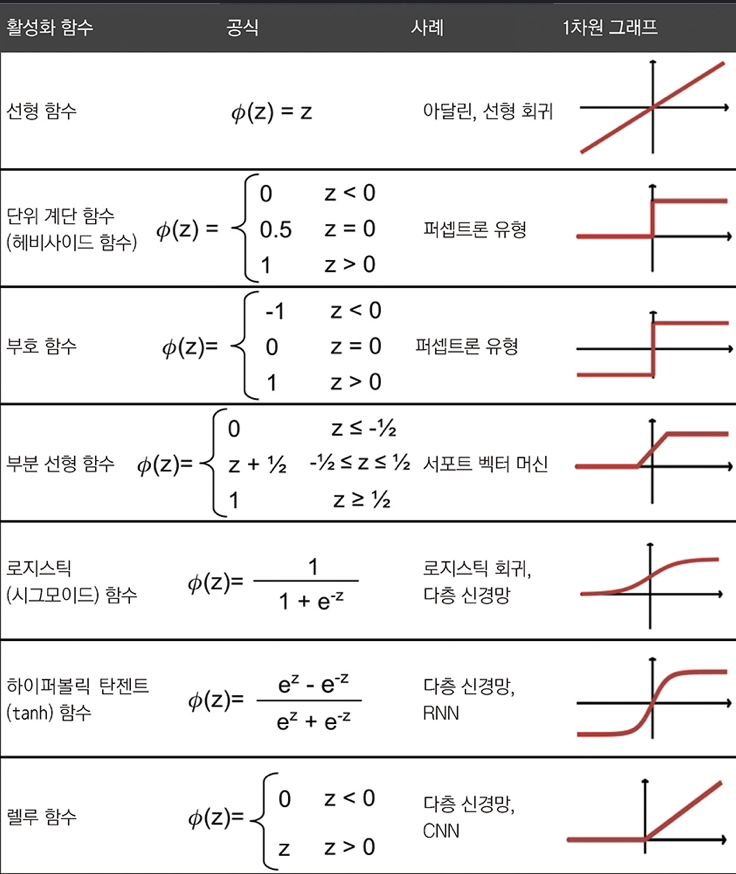
다층 신경망은 이론적으로 미분만 가능하다면 어떤 함수이든지 활성화 함수로 선택할 수 있다.
다만, 각각의 특징에 대해 살펴보고 상황에 따라 더 좋은 활성화 함수�를 선택할 수 있도록 하자.
인공 신경망은 대체로 (복잡한 문제를 해결하므로) 비선형 활성화 함수가 좋은 성능을 보인다. 그 종류를 확인해 보자.
시그모이드 함수의 일종으로 로지스틱 회귀 모델에서 사용되는 함수와 동일한 함수이다.
시그모이드는 뉴런 개념을 가장 비슷하게 흉내낸 함수이다.
그러나 큰 음수 입력이 들어오거나 시그모이드 함수가 0에 가까운 출력을 내리면 신경망이 매우 느리게 학습하게 된다. 이는 지역 최솟값에 갇힐 가능성이 높아지게 만든다.
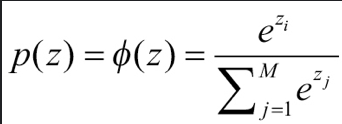
간접적인 argmax 함수라고 할 수 있다.
모든 확률을 지수적으로 바꾼 후에 정규화()시킨 것과 같다.
참고로, 다중 클래스 분류에서 사용하는 비용함수는 크로스 엔트로피(cross entropy)함수이다. 로지스틱 비용함수는 이것의 이진 분류 버전이라 할 수 있다.
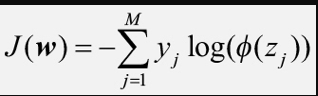
이것의 도함수는 로지스틱 비용함수와 동일하게 결과가 유도된다.
스케일이 조정된 로지스틱 함수라 할 수 있다.
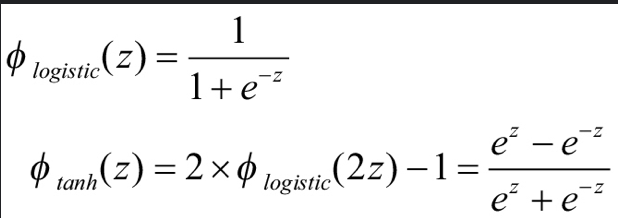
tanh함수나 로지스틱함수는 그래프의 특징 상 그레이디언트 소실 문제(vanishing gradient problem)를 가지고 있다.
이를 어느정도 해결한 함수가 ReLU이다.
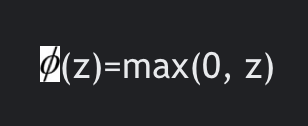
아래 그림을 통해 활성화 함수들을 한꺼번에 봐 보자.
Seq2Seq에서 RNN을 아예 빼버리고 attention으로 구성해보면 어떨까? → Transformer의 구조 현재는 seq2seq + attention에서는 하나의 벡터로…
2025/04/27
성# Language Model(LM)이란? 언어 모델이라는 건, 사실 다음에 올 단어를 확률로 예측하는 것이다. 이러한 언어 모델들을 어떻게 발전시켜왔는 지 살펴보자. 이미 이…
2025/04/27
이전 포스트에서 RNN에서 Vanishing Gradient로 인해 장기 의존성 문제가 있다는 사실을 이야기했다. 이런 Vanishing Gradient를 해결하기 위해 크게…
2025/04/27
기존 RNN의 병목 현상을 해결하기 위해 Attention이 등장했다. Decoder에서 한 단어를 예상할 때, 해당 단어와 특별히 관련되어 있는 Encoder의 특정 단어를…
2025/04/27



